# External (non-OpenAI) Pull Request Requirements
Before opening this Pull Request, please read the dedicated
"Contributing" markdown file or your PR may be closed:
https://github.com/openai/codex/blob/main/docs/contributing.md
If your PR conforms to our contribution guidelines, replace this text
with a detailed and high quality description of your changes.
Include a link to a bug report or enhancement request.
---------
Co-authored-by: Codex <noreply@openai.com>
- Changed `requires_mcp_tool_approval` to apply MCP spec defaults when
annotations are missing.
- Unannotated tools now default to:
- `readOnlyHint = false`
- `destructiveHint = true`
- `openWorldHint = true`
- This means unannotated MCP tools now go through approval/ARC
monitoring instead of silently bypassing it.
- Explicitly read-only tools still skip approval unless they are also
explicitly marked destructive.
**Previous behavior**
Failed open for missing annotations, which was unsafe for custom MCP
tools that omitted or forgot annotations.
---------
Co-authored-by: colby-oai <228809017+colby-oai@users.noreply.github.com>
## Summary
- keep legacy Windows restricted-token sandboxing as the supported
baseline
- support the split-policy subset that restricted-token can enforce
directly today
- support full-disk read, the same writable root set as legacy
`WorkspaceWrite`, and extra read-only carveouts under those writable
roots via additional deny-write ACLs
- continue to fail closed for unsupported split-only shapes, including
explicit unreadable (`none`) carveouts, reopened writable descendants
under read-only carveouts, and writable root sets that do not match the
legacy workspace roots
## Example
Given a filesystem policy like:
```toml
":root" = "read"
":cwd" = "write"
"./docs" = "read"
```
the restricted-token backend can keep the workspace writable while
denying writes under `docs` by layering an extra deny-write carveout on
top of the legacy workspace-write roots.
A policy like:
```toml
"/workspace" = "write"
"/workspace/docs" = "read"
"/workspace/docs/tmp" = "write"
```
still fails closed, because the unelevated backend cannot reopen the
nested writable descendant safely.
## Stack
-> fix: support split carveouts in windows restricted-token sandbox
#14172
fix: support split carveouts in windows elevated sandbox #14568
## Summary
- remove the fork-startup `build_initial_context` injection
- keep the reconstructed `reference_context_item` as the fork baseline
until the first real turn
- update fork-history tests and the request snapshot, and add a
`TODO(ccunningham)` for remaining nondiffable initial-context inputs
## Why
Fork startup was appending current-session initial context immediately
after reconstructing the parent rollout, then the first real turn could
emit context updates again. That duplicated model-visible context in the
child rollout.
## Impact
Forked sessions now behave like resume for context seeding: startup
reconstructs history and preserves the prior baseline, and the first
real turn handles any current-session context emission.
---------
Co-authored-by: Codex <noreply@openai.com>
## Summary
- Reuse the existing config path resolver for the macOS MDM managed
preferences layer so `writable_roots = ["~/code"]` expands the same way
as file-backed config
- keep the change scoped to the MDM branch in `config_loader`; the
current net diff is only `config_loader/mod.rs` plus focused regression
tests in `config_loader/tests.rs` and `config/service_tests.rs`
- research note: `resolve_relative_paths_in_config_toml(...)` is already
used in several existing configuration paths, including [CLI
overrides](74fda242d3/codex-rs/core/src/config_loader/mod.rs (L152-L163)),
[file-backed managed
config](74fda242d3/codex-rs/core/src/config_loader/mod.rs (L274-L285)),
[normal config-file
loading](74fda242d3/codex-rs/core/src/config_loader/mod.rs (L311-L331)),
[project `.codex/config.toml`
loading](74fda242d3/codex-rs/core/src/config_loader/mod.rs (L863-L865)),
and [role config
loading](74fda242d3/codex-rs/core/src/agent/role.rs (L105-L109))
## Validation
- `cargo fmt --all --check`
- `cargo test -p codex-core
managed_preferences_expand_home_directory_in_workspace_write_roots --
--nocapture`
- `cargo test -p codex-core
write_value_succeeds_when_managed_preferences_expand_home_directory_paths
-- --nocapture`
---------
Co-authored-by: Michael Bolin <mbolin@openai.com>
Co-authored-by: Michael Bolin <bolinfest@gmail.com>
## Why
This is a follow-up to #15360. That change fixed the `arg0` helper
setup, but `rmcp-client` still coerced stdio transport environment
values into UTF-8 `String`s before program resolution and process spawn.
If `PATH` or another inherited environment value contains non-UTF-8
bytes, that loses fidelity before it reaches `which` and `Command`.
## What changed
- change `create_env_for_mcp_server()` to return `HashMap<OsString,
OsString>` and read inherited values with `std::env::var_os()`
- change `TransportRecipe::Stdio.env`, `RmcpClient::new_stdio_client()`,
and `program_resolver::resolve()` to keep stdio transport env values in
`OsString` form within `rmcp-client`
- keep the `codex-core` config boundary stringly, but convert configured
stdio env values to `OsString` once when constructing the transport
- update the rmcp-client stdio test fixtures and callers to use
`OsString` env maps
- add a Unix regression test that verifies `create_env_for_mcp_server()`
preserves a non-UTF-8 `PATH`
## How to verify
- `cargo test -p codex-rmcp-client`
- `cargo test -p codex-core mcp_connection_manager`
- `just argument-comment-lint`
Targeted coverage in this change includes
`utils::tests::create_env_preserves_path_when_it_is_not_utf8`, while the
updated stdio transport path is exercised by the existing rmcp-client
tests that construct `RmcpClient::new_stdio_client()`.
- move the shared byte-based middle truncation logic from `core` into
`codex-utils-string`
- keep token-specific truncation in `codex-core` so rollout can reuse
the shared helper in the next stacked PR
---------
Co-authored-by: Codex <noreply@openai.com>
## Summary
- drop `sandbox_permissions` from the sandboxing `ExecOptions` and
`ExecRequest` adapter types
- remove the now-unused plumbing from shell, unified exec, JS REPL, and
apply-patch runtime call sites
- default reconstructed `ExecParams` to `SandboxPermissions::UseDefault`
where the lower-level API still requires the field
## Testing
- `just fmt`
- `just argument-comment-lint`
- `cargo test -p codex-core` (still running locally; first failures
observed in `suite::cli_stream::responses_mode_stream_cli`,
`suite::cli_stream::responses_mode_stream_cli_supports_openai_base_url_config_override`,
and
`suite::cli_stream::responses_mode_stream_cli_supports_openai_base_url_env_fallback`)
- create `codex-git-utils` and move the shared git helpers into it with
file moves preserved for diff readability
- move the `GitInfo` helpers out of `core` so stacked rollout work can
depend on the shared crate without carrying its own git info module
---------
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
Co-authored-by: Codex <noreply@openai.com>
## Why
`shell-tool-mcp` and the Bash fork are no longer needed, but the patched
zsh fork is still relevant for shell escalation and for the
DotSlash-backed zsh-fork integration tests.
Deleting the old `shell-tool-mcp` workflow also deleted the only
pipeline that rebuilt those patched zsh binaries. This keeps the package
removal, while preserving a small release path that can be reused
whenever `codex-rs/shell-escalation/patches/zsh-exec-wrapper.patch`
changes.
## What changed
- removed the `shell-tool-mcp` workspace package, its npm
packaging/release jobs, the Bash test fixture, and the remaining
Bash-specific compatibility wiring
- deleted the old `.github/workflows/shell-tool-mcp.yml` and
`.github/workflows/shell-tool-mcp-ci.yml` workflows now that their
responsibilities have been replaced or removed
- kept the zsh patch under
`codex-rs/shell-escalation/patches/zsh-exec-wrapper.patch` and updated
the `codex-rs/shell-escalation` docs/code to describe the zsh-based flow
directly
- added `.github/workflows/rust-release-zsh.yml` to build only the three
zsh binaries that `codex-rs/app-server/tests/suite/zsh` needs today:
- `aarch64-apple-darwin` on `macos-15`
- `x86_64-unknown-linux-musl` on `ubuntu-24.04`
- `aarch64-unknown-linux-musl` on `ubuntu-24.04`
- extracted the shared zsh build/smoke-test/stage logic into
`.github/scripts/build-zsh-release-artifact.sh`, made that helper
directly executable, and now invoke it directly from the workflow so the
Linux and macOS jobs only keep the OS-specific setup in YAML
- wired those standalone `codex-zsh-*.tar.gz` assets into
`rust-release.yml` and added `.github/dotslash-zsh-config.json` so
releases also publish a `codex-zsh` DotSlash file
- updated the checked-in `codex-rs/app-server/tests/suite/zsh` fixture
comments to explain that new releases come from the standalone zsh
assets, while the checked-in fixture remains pinned to the latest
historical release until a newer zsh artifact is published
- tightened a couple of follow-on cleanups in
`codex-rs/shell-escalation`: the `ExecParams::command` comment now
describes the shell `-c`/`-lc` string more clearly, and the README now
points at the same `git.code.sf.net` zsh source URL that the workflow
uses
## Testing
- `cargo test -p codex-shell-escalation`
- `just argument-comment-lint`
- `bash -n .github/scripts/build-zsh-release-artifact.sh`
- attempted `cargo test -p codex-core`; unrelated existing failures
remain, but the touched `tools::runtimes::shell::unix_escalation::*`
coverage passed during that run
## Summary
- trim contiguous developer/contextual-user pre-turn updates when
rollback cuts back to a user turn
- add a focused history regression test for the trim behavior
- update the rollback request-boundary snapshots to show the fixed
non-duplicating context shape
---------
Co-authored-by: Codex <noreply@openai.com>
built from #14256. PR description from @etraut-openai:
This PR addresses a hole in [PR
11802](https://github.com/openai/codex/pull/11802). The previous PR
assumed that app server clients would respond to token refresh failures
by presenting the user with an error ("you must log in again") and then
not making further attempts to call network endpoints using the expired
token. While they do present the user with this error, they don't
prevent further attempts to call network endpoints and can repeatedly
call `getAuthStatus(refreshToken=true)` resulting in many failed calls
to the token refresh endpoint.
There are three solutions I considered here:
1. Change the getAuthStatus app server call to return a null auth if the
caller specified "refreshToken" on input and the refresh attempt fails.
This will cause clients to immediately log out the user and return them
to the log in screen. This is a really bad user experience. It's also a
breaking change in the app server contract that could break third-party
clients.
2. Augment the getAuthStatus app server call to return an additional
field that indicates the state of "token could not be refreshed". This
is a non-breaking change to the app server API, but it requires
non-trivial changes for all clients to properly handle this new field
properly.
3. Change the getAuthStatus implementation to handle the case where a
token refresh fails by marking the AuthManager's in-memory access and
refresh tokens as "poisoned" so it they are no longer used. This is the
simplest fix that requires no client changes.
I chose option 3.
Here's Codex's explanation of this change:
When an app-server client asks `getAuthStatus(refreshToken=true)`, we
may try to refresh a stale ChatGPT access token. If that refresh fails
permanently (for example `refresh_token_reused`, expired, or revoked),
the old behavior was bad in two ways:
1. We kept the in-memory auth snapshot alive as if it were still usable.
2. Later auth checks could retry refresh again and again, creating a
storm of doomed `/oauth/token` requests and repeatedly surfacing the
same failure.
This is especially painful for app-server clients because they poll auth
status and can keep driving the refresh path without any real chance of
recovery.
This change makes permanent refresh failures terminal for the current
managed auth snapshot without changing the app-server API contract.
What changed:
- `AuthManager` now poisons the current managed auth snapshot in memory
after a permanent refresh failure, keyed to the unchanged `AuthDotJson`.
- Once poisoned, later refresh attempts for that same snapshot fail fast
locally without calling the auth service again.
- The poison is cleared automatically when auth materially changes, such
as a new login, logout, or reload of different auth state from storage.
- `getAuthStatus(includeToken=true)` now omits `authToken` after a
permanent refresh failure instead of handing out the stale cached bearer
token.
This keeps the current auth method visible to clients, avoids forcing an
immediate logout flow, and stops repeated refresh attempts for
credentials that cannot recover.
---------
Co-authored-by: Eric Traut <etraut@openai.com>
Follow up to #15357 by making proactive ChatGPT auth refresh depend on
the access token's JWT expiration instead of treating `last_refresh` age
as the primary source of truth.
### Summary
Make `FileWatcher` a reusable core component which can be built upon.
Extract skills-related logic into a separate `SkillWatcher`.
Introduce a composable `ThrottledWatchReceiver` to throttle filesystem
events, coalescing affected paths among them.
### Testing
Updated existing unit tests.
- Prefer plugin manifest `interface.displayName` for plugin labels.
- Preserve plugin provenance when handling `list_mcp_tools` so connector
`plugin_display_names` are not clobbered.
- Add a TUI test to ensure plugin-owned app mentions are deduped
correctly.
## Summary
- replace the second-compaction test fixtures with a single ordered
`/responses` sequence
- assert against the real recorded request order instead of aggregating
per-mock captures
- realign the second-summary assertion to the first post-compaction user
turn where the summary actually appears
## Root cause
`compact_resume_after_second_compaction_preserves_history` collected
requests from multiple `mount_sse_once_match` recorders. Overlapping
matchers could record the same HTTP request more than once, so the test
indexed into a duplicated synthetic list rather than the true request
stream. That made the summary assertion depend on matcher evaluation
order and platform-specific behavior.
## Impact
- makes the flaky test deterministic by removing duplicate request
capture from the assertion path
- keeps the change scoped to the test only
## Validation
- `just fmt`
- `just argument-comment-lint`
- `env -u CODEX_SANDBOX_NETWORK_DISABLED cargo test -p codex-core
compact_resume_after_second_compaction_preserves_history -- --nocapture`
- repeated the same targeted test 10 times
---------
Co-authored-by: Codex <noreply@openai.com>
Make the inter-agent communication start a turn
As part of this, we disable the v2 notifier to prevent some odd
behaviour where the agent restart working while you're talking to it for
example
Show all plugin marketplaces in the /plugins popup by removing the
`openai-curated` marketplace filter, and update plugin popup
copy/tests/snapshots to match the new behavior in both TUI codepaths.
## Summary
- move the pure sandbox policy transform helpers from `codex-core` into
`codex-sandboxing`
- move the corresponding unit tests with the extracted implementation
- update `core` and `app-server` callers to import the moved APIs
directly, without re-exports or proxy methods
## Testing
- cargo test -p codex-sandboxing
- cargo test -p codex-core sandboxing
- cargo test -p codex-app-server --lib
- just fix -p codex-sandboxing
- just fix -p codex-core
- just fix -p codex-app-server
- just fmt
- just argument-comment-lint
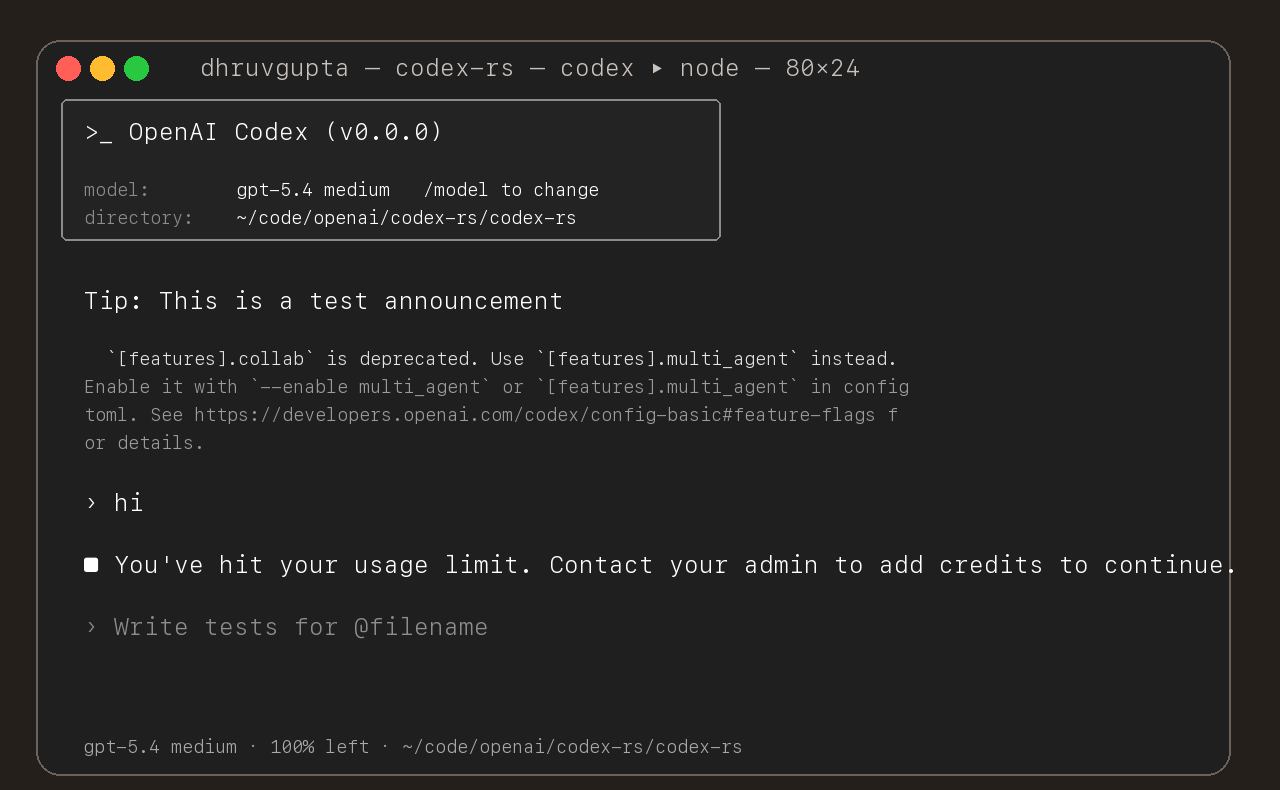
## Summary
- update the self-serve business usage-based limit message to direct
users to their admin for additional credits
- add a focused unit test for the self_serve_business_usage_based plan
branch
Added also:
If you are at a rate limit but you still have credits, codex cli would
tell you to switch the model. We shouldnt do this if you have credits so
fixed this.
## Test
- launched the source-built CLI and verified the updated message is
shown for the self-serve business usage-based plan
## Summary
- move macOS permission merging/intersection logic and tests from
`codex-core` into `codex-sandboxing`
- move seatbelt policy builders, permissions logic, SBPL assets, and
their tests into `codex-sandboxing`
- keep `codex-core` owning only the seatbelt spawn wrapper and switch
call sites to import the moved APIs directly
## Notes
- no re-exports added
- moved the seatbelt tests with the implementation so internal helpers
could stay private
- local verification is still finishing while this PR is open
## Summary
- add a new `codex-sandboxing` crate for sandboxing extraction work
- move the pure Linux sandbox argv builders and their unit tests out of
`codex-core`
- keep `core::landlock` as the spawn wrapper and update direct callers
to use `codex_sandboxing::landlock`
## Testing
- `cargo test -p codex-sandboxing`
- `cargo test -p codex-core landlock`
- `cargo test -p codex-cli debug_sandbox`
- `just argument-comment-lint`
## Notes
- this is step 1 of the move plan aimed at minimizing per-PR diffs
- no re-exports or no-op proxy methods were added
## Summary
- add `ForkSnapshotMode` to `ThreadManager::fork_thread` so callers can
request either a committed snapshot or an interrupted snapshot
- share the model-visible `<turn_aborted>` history marker between the
live interrupt path and interrupted forks
- update the small set of direct fork callsites to pass
`ForkSnapshotMode::Committed`
Note: this enables /btw to work similarly as Esc to interrupt (hopefully
somewhat in distribution)
---------
Co-authored-by: Codex <noreply@openai.com>
## What changed
- adds a targeted snapshot test for rollback with contextual diffs in
`codex_tests.rs`
- snapshots the exact model-visible request input before the rolled-back
turn and on the follow-up request after rollback
- shows the duplicate developer and environment context pair appearing
again before the follow-up user message
## Why
Rollback currently rewinds the reference context baseline without
rewinding the live session overrides. On the next turn, the same
contextual diff is emitted again and duplicated in the request sent to
the model.
## Impact
- makes the regression visible in a canonical snapshot test
- keeps the snapshot on the shared `context_snapshot` path without
adding new formatting helpers
- gives a direct repro for future fixes to rollback/context
reconstruction
---------
Co-authored-by: Codex <noreply@openai.com>
## Summary
Adds support for approvals_reviewer to `Op::UserTurn` so we can migrate
`[CodexMessageProcessor::turn_start]` to use Op::UserTurn
## Testing
- [x] Adds quick test for the new field
Co-authored-by: Codex <noreply@openai.com>
Use `serde` to encode the inter agent communication to an assistant
message and use the decode to see if this is such a message
Note: this assume serde on small pattern is fast enough
- add `PreToolUse` hook for bash-like tool execution only at first
- block shell execution before dispatch with deny-only hook behavior
- introduces common.rs matcher framework for matching when hooks are run
example run:
```
› run three parallel echo commands, and the second one should echo "[block-pre-tool-use]" as a test
• Running the three echo commands in parallel now and I’ll report the output directly.
• Running PreToolUse hook: name for demo pre tool use hook
• Running PreToolUse hook: name for demo pre tool use hook
• Running PreToolUse hook: name for demo pre tool use hook
PreToolUse hook (completed)
warning: wizard-tower PreToolUse demo inspected Bash: echo "first parallel echo"
PreToolUse hook (blocked)
warning: wizard-tower PreToolUse demo blocked a Bash command on purpose.
feedback: PreToolUse demo blocked the command. Remove [block-pre-tool-use] to continue.
PreToolUse hook (completed)
warning: wizard-tower PreToolUse demo inspected Bash: echo "third parallel echo"
• Ran echo "first parallel echo"
└ first parallel echo
• Ran echo "third parallel echo"
└ third parallel echo
• Three little waves went out in parallel.
1. printed first parallel echo
2. was blocked before execution because it contained the exact test string [block-pre-tool-use]
3. printed third parallel echo
There was also an unrelated macOS defaults warning around the successful commands, but the echoes
themselves worked fine. If you want, I can rerun the second one with a slightly modified string so
it passes cleanly.
```
## Summary
- capture the last guardian `EventMsg::Error` while waiting for review
completion
- reuse that error as the denial rationale when the review turn
completes without an assessment payload
- add a regression test for the `/responses` HTTP 400 path
## Testing
- `just fmt`
- `cargo test -p codex-core
guardian_review_surfaces_responses_api_errors_in_rejection_reason`
- `just argument-comment-lint -p codex-core`
## Notes
- `cargo test -p codex-core` still fails on the pre-existing unrelated
test
`tools::js_repl::tests::js_repl_imported_local_files_can_access_repl_globals`
in this environment (`mktemp ... Operation not permitted` while
downloading `dotslash`)
Co-authored-by: Codex <noreply@openai.com>
## Summary
Fix a managed ChatGPT auth bug where a stale Codex process could
proactively refresh using an old in-memory refresh token even after
another process had already rotated auth on disk.
This changes the proactive `AuthManager::auth()` path to reuse the
existing guarded `refresh_token()` flow instead of calling the refresh
endpoint directly from cached auth state.
## Original Issue
Users reported repeated `codexd` log lines like:
```text
ERROR codex_core::auth: Failed to refresh token: error sending request for url (https://auth.openai.com/oauth/token)
```
In practice this showed up most often when multiple `codexd` processes
were left running. Killing the extra processes stopped the noise, which
suggested the issue was caused by stale auth state across processes
rather than invalid user credentials.
## Diagnosis
The bug was in the proactive refresh path used by `AuthManager::auth()`:
- Process A could refresh successfully, rotate refresh token `R0` to
`R1`, and persist the updated auth state plus `last_refresh` to disk.
- Process B could keep an older auth snapshot cached in memory, still
holding `R0` and the old `last_refresh`.
- Later, when Process B called `auth()`, it checked staleness from its
cached in-memory auth instead of first reloading from disk.
- Because that cached `last_refresh` was stale, Process B would
proactively call `/oauth/token` with stale refresh token `R0`.
- On failure, `auth()` logged the refresh error but kept returning the
same stale cached auth, so repeated `auth()` calls could keep retrying
with dead state.
This differed from the existing unauthorized-recovery flow, which
already did the safer thing: guarded reload from disk first, then
refresh only if the on-disk auth was unchanged.
## What Changed
- Switched proactive refresh in `AuthManager::auth()` to:
- do a pure staleness check on cached auth
- call `refresh_token()` when stale
- return the original cached auth on genuine refresh failure, preserving
existing outward behavior
- Removed the direct proactive refresh-from-cached-state path
- Added regression tests covering:
- stale cached auth with newer same-account auth already on disk
- the same scenario even when the refresh endpoint would fail if called
## Why This Fix
`refresh_token()` already contains the right cross-process safety
behavior:
- guarded reload from disk
- same-account verification
- skip-refresh when another process already changed auth
Reusing that path makes proactive refresh consistent with unauthorized
recovery and prevents stale processes from trying to refresh
already-rotated tokens.
## Testing
Test shape:
- create a fresh temp `CODEX_HOME` from `~/.codex/auth.json`
- force `last_refresh` to an old timestamp so proactive refresh is
required
- start two long-lived helper processes against the same auth file
- start `B` first so it caches stale auth and sleeps
- start `A` second so it refreshes first
- point both at a local mock `/oauth/token` server
- inspect whether `B` makes a second refresh request with the stale
in-memory token, or reloads the rotated token from disk
### Before the fix
The repro showed the bug clearly: the mock server saw two refreshes with
the same stale token, `A` rotated to a new token, and `B` still returned
the stale token instead of reloading from disk.
```text
POST /oauth/token refresh_token=rt_j6s0...
POST /oauth/token refresh_token=rt_j6s0...
B:cached_before=rt_j6s0...
B:cached_after=rt_j6s0...
B:returned=rt_j6s0...
A:cached_before=rt_j6s0...
A:cached_after=rotated-refresh-token-logged-run-v2
A:returned=rotated-refresh-token-logged-run-v2
```
### After the fix
After the fix, the mock server saw only one refresh request. `A`
refreshed once, and `B` started with the stale token but reloaded and
returned the rotated token.
```text
POST /oauth/token refresh_token=rt_j6s0...
B:cached_before=rt_j6s0...
B:cached_after=rotated-refresh-token-fix-branch
B:returned=rotated-refresh-token-fix-branch
A:cached_before=rt_j6s0...
A:cached_after=rotated-refresh-token-fix-branch
A:returned=rotated-refresh-token-fix-branch
```
This shows the new behavior: `A` refreshes once, then `B` reuses the
updated auth from disk instead of making a second refresh request with
the stale token.
Send input now sends messages as assistant message and with this format:
```
author: /root/worker_a
recipient: /root/worker_a/tester
other_recipients: []
Content: bla bla bla. Actual content. Only text for now
```
## Summary
- queue input after the user submits `/compact` until that manual
compact turn ends
- mirror the same behavior in the app-server TUI
- add regressions for input queued before compact starts and while it is
running
Co-authored-by: Codex <noreply@openai.com>
## Why
Fixes [#15283](https://github.com/openai/codex/issues/15283), where
sandboxed tool calls fail on older distro `bubblewrap` builds because
`/usr/bin/bwrap` does not understand `--argv0`. The upstream [bubblewrap
v0.9.0 release
notes](https://github.com/containers/bubblewrap/releases/tag/v0.9.0)
explicitly call out `Add --argv0`. Flipping `use_legacy_landlock`
globally works around that compatibility bug, but it also weakens the
default Linux sandbox and breaks proxy-routed and split-policy cases
called out in review.
The follow-up Linux CI failure was in the new launcher test rather than
the launcher logic: the fake `bwrap` helper stayed open for writing, so
Linux would not exec it. This update also closes the user-visibility gap
from review by surfacing the same startup warning when `/usr/bin/bwrap`
is present but too old for `--argv0`, not only when it is missing.
## What Changed
- keep `use_legacy_landlock` default-disabled
- teach `codex-rs/linux-sandbox/src/launcher.rs` to fall back to the
vendored bubblewrap build when `/usr/bin/bwrap` does not advertise
`--argv0` support
- add launcher tests for supported, unsupported, and missing system
`bwrap`
- write the fake `bwrap` test helper to a closed temp path so the
supported-path launcher test works on Linux too
- extend the startup warning path so Codex warns when `/usr/bin/bwrap`
is missing or too old to support `--argv0`
- mirror the warning/fallback wording across
`codex-rs/linux-sandbox/README.md` and `codex-rs/core/README.md`,
including that the fallback is the vendored bubblewrap compiled into the
binary
- cite the upstream `bubblewrap` release that introduced `--argv0`
## Verification
- `bazel test --config=remote --platforms=//:rbe
//codex-rs/linux-sandbox:linux-sandbox-unit-tests
--test_filter=launcher::tests::prefers_system_bwrap_when_help_lists_argv0
--test_output=errors`
- `cargo test -p codex-core system_bwrap_warning`
- `cargo check -p codex-exec -p codex-tui -p codex-tui-app-server -p
codex-app-server`
- `just argument-comment-lint`
{kind=link}