## Summary
- add `self_serve_business_usage_based` and `enterprise_cbp_usage_based`
to the public/internal plan enums and regenerate the app-server + Python
SDK artifacts
- map both plans through JWT login and backend rate-limit payloads, then
bucket them with the existing Team/Business entitlement behavior in
cloud requirements, usage-limit copy, tooltips, and status display
- keep the earlier display-label remap commit on this branch so the new
Team-like and Business-like plans render consistently in the UI
## Testing
- `just write-app-server-schema`
- `uv run --project sdk/python python
sdk/python/scripts/update_sdk_artifacts.py generate-types`
- `just fix -p codex-protocol -p codex-login -p codex-core -p
codex-backend-client -p codex-cloud-requirements -p codex-tui -p
codex-tui-app-server -p codex-backend-openapi-models`
- `just fmt`
- `just argument-comment-lint`
- `cargo test -p codex-protocol
usage_based_plan_types_use_expected_wire_names`
- `cargo test -p codex-login usage_based`
- `cargo test -p codex-backend-client usage_based`
- `cargo test -p codex-cloud-requirements usage_based`
- `cargo test -p codex-core usage_limit_reached_error_formats_`
- `cargo test -p codex-tui plan_type_display_name_remaps_display_labels`
- `cargo test -p codex-tui remapped`
- `cargo test -p codex-tui-app-server
plan_type_display_name_remaps_display_labels`
- `cargo test -p codex-tui-app-server remapped`
- `cargo test -p codex-tui-app-server
preserves_usage_based_plan_type_wire_name`
## Notes
- a broader multi-crate `cargo test` run still hits unrelated existing
guardian-approval config failures in
`codex-rs/core/src/config/config_tests.rs`
## Why
`token_data` is owned by `codex-login`, but `codex-core` was still
re-exporting it. That let callers pull auth token types through
`codex-core`, which keeps otherwise unrelated crates coupled to
`codex-core` and makes `codex-core` more of a build-graph bottleneck.
## What changed
- remove the `codex-core` re-export of `codex_login::token_data`
- update the remaining `codex-core` internals that used
`crate::token_data` to import `codex_login::token_data` directly
- update downstream callers in `codex-rs/chatgpt`,
`codex-rs/tui_app_server`, `codex-rs/app-server/tests/common`, and
`codex-rs/core/tests` to import `codex_login::token_data` directly
- add explicit `codex-login` workspace dependencies and refresh lock
metadata for crates that now depend on it directly
## Validation
- `cargo test -p codex-chatgpt --locked`
- `just argument-comment-lint`
- `just bazel-lock-update`
- `just bazel-lock-check`
## Notes
- attempted `cargo test -p codex-core --locked` and `cargo test -p
codex-core auth_refresh --locked`, but both ran out of disk while
linking `codex-core` test binaries in the local environment
- move the shared byte-based middle truncation logic from `core` into
`codex-utils-string`
- keep token-specific truncation in `codex-core` so rollout can reuse
the shared helper in the next stacked PR
---------
Co-authored-by: Codex <noreply@openai.com>
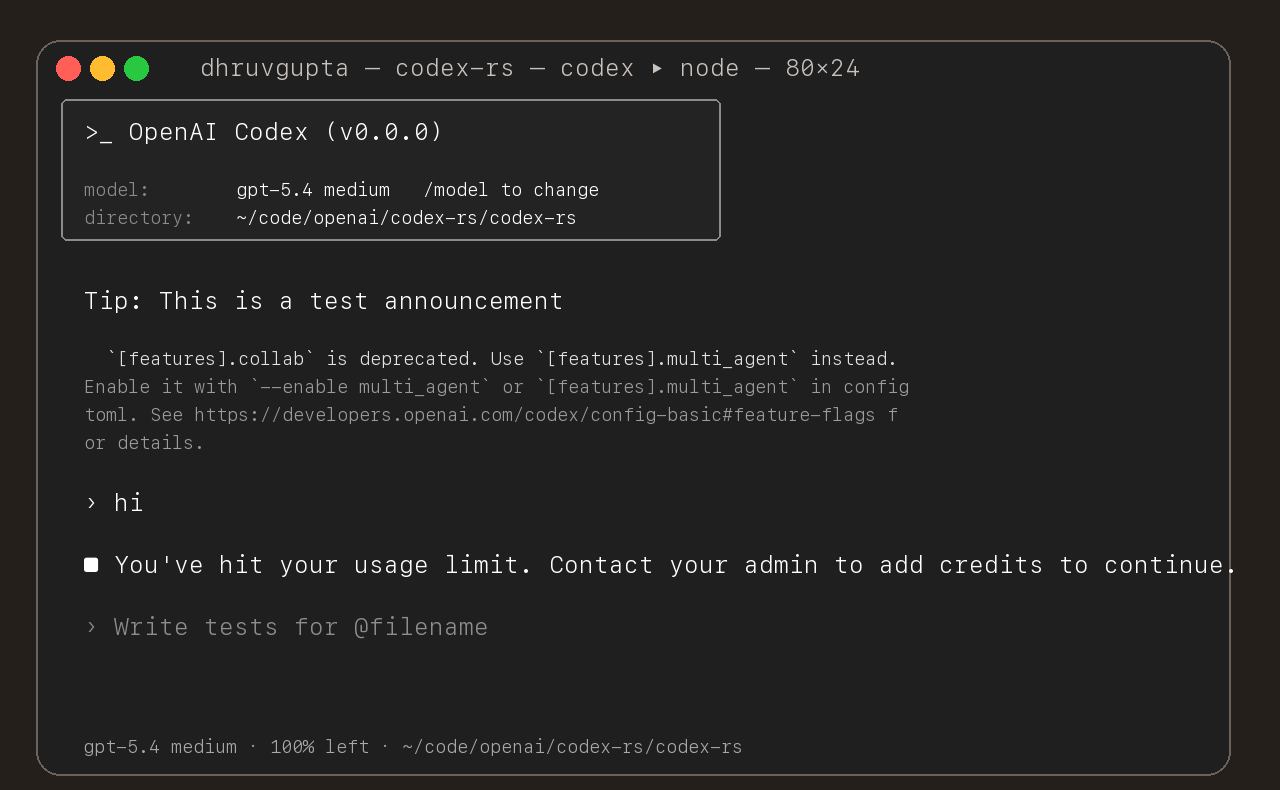
## Summary
- update the self-serve business usage-based limit message to direct
users to their admin for additional credits
- add a focused unit test for the self_serve_business_usage_based plan
branch
Added also:
If you are at a rate limit but you still have credits, codex cli would
tell you to switch the model. We shouldnt do this if you have credits so
fixed this.
## Test
- launched the source-built CLI and verified the updated message is
shown for the self-serve business usage-based plan
- Move the auth implementation and token data into codex-login.
- Keep codex-core re-exporting that surface from codex-login for
existing callers.
---------
Co-authored-by: Codex <noreply@openai.com>
CXC-392
[With
401](https://openai.sentry.io/issues/7333870443/?project=4510195390611458&query=019ce8f8-560c-7f10-a00a-c59553740674&referrer=issue-stream)
<img width="1909" height="555" alt="401 auth tags in Sentry"
src="https://github.com/user-attachments/assets/412ea950-61c4-4780-9697-15c270971ee3"
/>
- auth_401_*: preserved facts from the latest unauthorized response snapshot
- auth_*: latest auth-related facts from the latest request attempt
- auth_recovery_*: unauthorized recovery state and follow-up result
Without 401
<img width="1917" height="522" alt="happy-path auth tags in Sentry"
src="https://github.com/user-attachments/assets/3381ed28-8022-43b0-b6c0-623a630e679f"
/>
###### Summary
- Add client-visible 401 diagnostics for auth attachment, upstream auth classification, and 401 request id / cf-ray correlation.
- Record unauthorized recovery mode, phase, outcome, and retry/follow-up status without changing auth behavior.
- Surface the highest-signal auth and recovery fields on uploaded client bug reports so they are usable in Sentry.
- Preserve original unauthorized evidence under `auth_401_*` while keeping follow-up result tags separate.
###### Rationale (from spec findings)
- The dominant bucket needed proof of whether the client attached auth before send or upstream still classified the request as missing auth.
- Client uploads needed to show whether unauthorized recovery ran and what the client tried next.
- Request id and cf-ray needed to be preserved on the unauthorized response so server-side correlation is immediate.
- The bug-report path needed the same auth evidence as the request telemetry path, otherwise the observability would not be operationally useful.
###### Scope
- Add auth 401 and unauthorized-recovery observability in `codex-rs/core`, `codex-rs/codex-api`, and `codex-rs/otel`, including feedback-tag surfacing.
- Keep auth semantics, refresh behavior, retry behavior, endpoint classification, and geo-denial follow-up work out of this PR.
###### Trade-offs
- This exports only safe auth evidence: header presence/name, upstream auth classification, request ids, and recovery state. It does not export token values or raw upstream bodies.
- This keeps websocket connection reuse as a transport clue because it can help distinguish stale reused sessions from fresh reconnects.
- Misroute/base-url classification and geo-denial are intentionally deferred to a separate follow-up PR so this review stays focused on the dominant auth 401 bucket.
###### Client follow-up
- PR 2 will add misroute/provider and geo-denial observability plus the matching feedback-tag surfacing.
- A separate host/app-server PR should log auth-decision inputs so pre-send host auth state can be correlated with client request evidence.
- `device_id` remains intentionally separate until there is a safe existing source on the feedback upload path.
###### Testing
- `cargo test -p codex-core refresh_available_models_sorts_by_priority`
- `cargo test -p codex-core emit_feedback_request_tags_`
- `cargo test -p codex-core emit_feedback_auth_recovery_tags_`
- `cargo test -p codex-core auth_request_telemetry_context_tracks_attached_auth_and_retry_phase`
- `cargo test -p codex-core extract_response_debug_context_decodes_identity_headers`
- `cargo test -p codex-core identity_auth_details`
- `cargo test -p codex-core telemetry_error_messages_preserve_non_http_details`
- `cargo test -p codex-core --all-features --no-run`
- `cargo test -p codex-otel otel_export_routing_policy_routes_api_request_auth_observability`
- `cargo test -p codex-otel otel_export_routing_policy_routes_websocket_connect_auth_observability`
- `cargo test -p codex-otel otel_export_routing_policy_routes_websocket_request_transport_observability`
## Why
PR #13783 moved the `codex.rs` unit tests into `codex_tests.rs`. This
applies the same extraction pattern across the rest of `codex-rs/core`
so the production modules stay focused on runtime code instead of large
inline test blocks.
Keeping the tests in sibling files also makes follow-up edits easier to
review because product changes no longer have to share a file with
hundreds or thousands of lines of test scaffolding.
## What changed
- replaced each inline `mod tests { ... }` in `codex-rs/core/src/**`
with a path-based module declaration
- moved each extracted unit test module into a sibling `*_tests.rs`
file, using `mod_tests.rs` for `mod.rs` modules
- preserved the existing `cfg(...)` guards and module-local structure so
the refactor remains structural rather than behavioral
## Testing
- `cargo test -p codex-core --lib` (`1653 passed; 0 failed; 5 ignored`)
- `just fix -p codex-core`
- `cargo fmt --check`
- `cargo shear`
### Description
#### Summary
Introduces the core plumbing required for structured network approvals
#### What changed
- Added structured network policy decision modeling in core.
- Added approval payload/context types needed for network approval
semantics.
- Wired shell/unified-exec runtime plumbing to consume structured
decisions.
- Updated related core error/event surfaces for structured handling.
- Updated protocol plumbing used by core approval flow.
- Included small CLI debug sandbox compatibility updates needed by this
layer.
#### Why
establishes the minimal backend foundation for network approvals without
yet changing high-level orchestration or TUI behavior.
#### Notes
- Behavior remains constrained by existing requirements/config gating.
- Follow-up PRs in the stack handle orchestration, UX, and app-server
integration.
---------
Co-authored-by: Codex <199175422+chatgpt-codex-connector[bot]@users.noreply.github.com>
# External (non-OpenAI) Pull Request Requirements
Before opening this Pull Request, please read the dedicated
"Contributing" markdown file or your PR may be closed:
https://github.com/openai/codex/blob/main/docs/contributing.md
If your PR conforms to our contribution guidelines, replace this text
with a detailed and high quality description of your changes.
Include a link to a bug report or enhancement request.
Added multi-limit support end-to-end by carrying limit_name in
rate-limit snapshots and handling multiple buckets instead of only
codex.
Extended /usage client parsing to consume additional_rate_limits
Updated TUI /status and in-memory state to store/render per-limit
snapshots
Extended app-server rate-limit read response: kept rate_limits and added
rate_limits_by_name.
Adjusted usage-limit error messaging for non-default codex limit buckets
###### Problem
Users get generic 429s with no guidance when a model is at capacity.
###### Solution
Detect model-cap headers, surface a clear “try a different model”
message, and keep behavior non‑intrusive (no auto‑switch).
###### Scope
CLI/TUI only; protocol + error mapping updated to carry model‑cap info.
###### Tests
- just fmt
- cargo test -p codex-tui
- cargo test -p codex-core --lib
shell_snapshot::tests::try_new_creates_and_deletes_snapshot_file --
--nocapture (ran in isolated env)
- validate local build with backend
<img width="719" height="845" alt="image"
src="https://github.com/user-attachments/assets/1470b33d-0974-4b1f-b8e6-d11f892f4b54"
/>
# External (non-OpenAI) Pull Request Requirements
Before opening this Pull Request, please read the dedicated
"Contributing" markdown file or your PR may be closed:
https://github.com/openai/codex/blob/main/docs/contributing.md
If your PR conforms to our contribution guidelines, replace this text
with a detailed and high quality description of your changes.
Include a link to a bug report or enhancement request.
- Inline response recording during streaming: `run_turn` now records
items as they arrive instead of building a `ProcessedResponseItem` list
and post‑processing via `process_items`.
- Simplify turn handling: `handle_output_item_done` returns the
follow‑up signal + optional tool future; `needs_follow_up` is set only
there, and in‑flight tool futures are drained once at the end (errors
logged, no extra state writes).
- Flattened stream loop: removed `process_items` indirection and the
extra output queue
- - Tests: relaxed `tool_parallelism::tool_results_grouped` to allow any
completion order while still requiring matching call/output IDs.
If an image can't be read by the API, it will poison the entire history,
preventing any new turn on the conversation.
This detect such cases and replace the image by a placeholder
This reverts commit c2ec477d93.
# External (non-OpenAI) Pull Request Requirements
Before opening this Pull Request, please read the dedicated
"Contributing" markdown file or your PR may be closed:
https://github.com/openai/codex/blob/main/docs/contributing.md
If your PR conforms to our contribution guidelines, replace this text
with a detailed and high quality description of your changes.
Include a link to a bug report or enhancement request.
Expand the rate-limit cache/TUI: store credit snapshots alongside
primary and secondary windows, render “Credits” when the backend reports
they exist (unlimited vs rounded integer balances)
- This PR is to make it on path for truncating by tokens. This path will
be initially used by unified exec and context manager (responsible for
MCP calls mainly).
- We are exposing new config `calls_output_max_tokens`
- Use `tokens` as the main budget unit but truncate based on the model
family by Introducing `TruncationPolicy`.
- Introduce `truncate_text` as a router for truncation based on the
mode.
In next PRs:
- remove truncate_with_line_bytes_budget
- Add the ability to the model to override the token budget.
### Motivation
When Codex is launched from a region where Cloudflare blocks access (for
example, Russia), the CLI currently dumps Cloudflare’s entire HTML error
page. This isn’t actionable and makes it hard for users to understand
what happened. We want to detect the Cloudflare block and show a
concise, user-friendly explanation instead.
### What Changed
- Added CLOUDFLARE_BLOCKED_MESSAGE and a friendly_message() helper to
UnexpectedResponseError. Whenever we see a 403 whose body contains the
Cloudflare block notice, we now emit a single-line message (Access
blocked by Cloudflare…) while preserving the HTTP status and request id.
All other responses keep the original behaviour.
- Added two focused unit tests:
- unexpected_status_cloudflare_html_is_simplified ensures the Cloudflare
HTML case yields the friendly message.
- unexpected_status_non_html_is_unchanged confirms plain-text 403s still
return the raw body.
### Testing
- cargo build -p codex-cli
- cargo test -p codex-core
- just fix -p codex-core
- cargo test --all-features
---------
Co-authored-by: Eric Traut <etraut@openai.com>
This PR makes an "insufficient quota" error fatal so we don't attempt to
retry it multiple times in the agent loop.
We have multiple bug reports from users about intermittent retry
behaviors, and this could explain some of them. With this change, we'll
eliminate the retries and surface a clear error message.
The PR is a nearly identical copy of [this
PR](https://github.com/openai/codex/pull/4837) contributed by
@abimaelmartell. The original PR has gone stale. Rather than wait for
the contributor to resolve merge conflicts, I wanted to get this change
in.
Currently, when the access token expires, we attempt to use the refresh
token to acquire a new access token. This works most of the time.
However, there are situations where the refresh token is expired,
exhausted (already used to perform a refresh), or revoked. In those
cases, the current logic treats the error as transient and attempts to
retry it repeatedly.
This PR changes the token refresh logic to differentiate between
permanent and transient errors. It also changes callers to treat the
permanent errors as fatal rather than retrying them. And it provides
better error messages to users so they understand how to address the
problem. These error messages should also help us further understand why
we're seeing examples of refresh token exhaustion.
Here is the error message in the CLI. The same text appears within the
extension.
<img width="863" height="38" alt="image"
src="https://github.com/user-attachments/assets/7ffc0d08-ebf0-4900-b9a9-265064202f4f"
/>
I also correct the spelling of "Re-connecting", which shouldn't have a
hyphen in it.
Testing: I manually tested these code paths by adding temporary code to
programmatically cause my refresh token to be exhausted (by calling the
token refresh endpoint in a tight loop more than 50 times). I then
simulated an access token expiration, which caused the token refresh
logic to be invoked. I confirmed that the updated logic properly handled
the error condition.
Note: We earlier discussed the idea of forcefully logging out the user
at the point where token refresh failed. I made several attempts to do
this, and all of them resulted in a bad UX. It's important to surface
this error to users in a way that explains the problem and tells them
that they need to log in again. We also previously discussed deleting
the auth.json file when this condition is detected. That also creates
problems because it effectively changes the auth status from logged in
to logged out, and this causes odd failures and inconsistent UX. I think
it's therefore better not to delete auth.json in this case. If the user
closes the CLI or VSCE and starts it again, we properly detect that the
access token is expired and the refresh token is "dead", and we force
the user to go through the login flow at that time.
This should address aspects of #6191, #5679, and #5505
Hi OpenAI Codex team, currently "Visit chatgpt.com/codex/settings/usage
for up-to-date information on rate limits and credits" message in status
card and error messages. For now, without the "https://" prefix, the
link cannot be clicked directly from most terminals or chat interfaces.
<img width="636" height="127" alt="Screenshot 2025-11-02 at 22 47 06"
src="https://github.com/user-attachments/assets/5ea11e8b-fb74-451c-85dc-f4d492b2678b"
/>
---
The fix is intent to improve this issue:
- It makes the link clickable in terminals that support it, hence better
accessibility
- It follows standard URL formatting practices
- It maintains consistency with other links in the application (like the
existing "https://openai.com/chatgpt/pricing" links)
Thank you!
Currently we collect all all turn items in a vector, then we add it to
the history on success. This result in losing those items on errors
including aborting `ctrl+c`.
This PR:
- Adds the ability for the tool call to handle cancellation
- bubble the turn items up to where we are recording this info
Admittedly, this logic is an ad-hoc logic that doesn't handle a lot of
error edge cases. The right thing to do is recording to the history on
the spot as `items`/`tool calls output` come. However, this isn't
possible because of having different `task_kind` that has different
`conversation_histories`. The `try_run_turn` has no idea what thread are
we using. We cannot also pass an `arc` to the `conversation_histories`
because it's a private element of `state`.
That's said, `abort` is the most common case and we should cover it
until we remove `task kind`
The backend will be returning unix timestamps (seconds since epoch)
instead of RFC 3339 strings. This will make it more ergonomic for
developers to integrate against - no string parsing.
This change ensures that we store the absolute time instead of relative
offsets of when the primary and secondary rate limits will reset.
Previously these got recalculated relative to current time, which leads
to the displayed reset times to change over time, including after doing
a codex resume.
For previously changed sessions, this will cause the reset times to not
show due to this being a breaking change:
<img width="524" height="55" alt="Screenshot 2025-10-17 at 5 14 18 PM"
src="https://github.com/user-attachments/assets/53ebd43e-da25-4fef-9c47-94a529d40265"
/>
Fixes https://github.com/openai/codex/issues/4761
In the past, we were treating `input exceeded context window` as a
streaming error and retrying on it. Retrying on it has no point because
it won't change the behavior. In this PR, we surface the error to the
client without retry and also send a token count event to indicate that
the context window is full.
<img width="650" height="125" alt="image"
src="https://github.com/user-attachments/assets/c26b1213-4c27-4bfc-90f4-51a270a3efd5"
/>
# Tool System Refactor
- Centralizes tool definitions and execution in `core/src/tools/*`:
specs (`spec.rs`), handlers (`handlers/*`), router (`router.rs`),
registry/dispatch (`registry.rs`), and shared context (`context.rs`).
One registry now builds the model-visible tool list and binds handlers.
- Router converts model responses to tool calls; Registry dispatches
with consistent telemetry via `codex-rs/otel` and unified error
handling. Function, Local Shell, MCP, and experimental `unified_exec`
all flow through this path; legacy shell aliases still work.
- Rationale: reduce per‑tool boilerplate, keep spec/handler in sync, and
make adding tools predictable and testable.
Example: `read_file`
- Spec: `core/src/tools/spec.rs` (see `create_read_file_tool`,
registered by `build_specs`).
- Handler: `core/src/tools/handlers/read_file.rs` (absolute `file_path`,
1‑indexed `offset`, `limit`, `L#: ` prefixes, safe truncation).
- E2E test: `core/tests/suite/read_file.rs` validates the tool returns
the requested lines.
## Next steps:
- Decompose `handle_container_exec_with_params`
- Add parallel tool calls
We continue the separation between `codex app-server` and `codex
mcp-server`.
In particular, we introduce a new crate, `codex-app-server-protocol`,
and migrate `codex-rs/protocol/src/mcp_protocol.rs` into it, renaming it
`codex-rs/app-server-protocol/src/protocol.rs`.
Because `ConversationId` was defined in `mcp_protocol.rs`, we move it
into its own file, `codex-rs/protocol/src/conversation_id.rs`, and
because it is referenced in a ton of places, we have to touch a lot of
files as part of this PR.
We also decide to get away from proper JSON-RPC 2.0 semantics, so we
also introduce `codex-rs/app-server-protocol/src/jsonrpc_lite.rs`, which
is basically the same `JSONRPCMessage` type defined in `mcp-types`
except with all of the `"jsonrpc": "2.0"` removed.
Getting rid of `"jsonrpc": "2.0"` makes our serialization logic
considerably simpler, as we can lean heavier on serde to serialize
directly into the wire format that we use now.
{kind=link}