- Changed `requires_mcp_tool_approval` to apply MCP spec defaults when
annotations are missing.
- Unannotated tools now default to:
- `readOnlyHint = false`
- `destructiveHint = true`
- `openWorldHint = true`
- This means unannotated MCP tools now go through approval/ARC
monitoring instead of silently bypassing it.
- Explicitly read-only tools still skip approval unless they are also
explicitly marked destructive.
**Previous behavior**
Failed open for missing annotations, which was unsafe for custom MCP
tools that omitted or forgot annotations.
---------
Co-authored-by: colby-oai <228809017+colby-oai@users.noreply.github.com>
## Summary
- remove the fork-startup `build_initial_context` injection
- keep the reconstructed `reference_context_item` as the fork baseline
until the first real turn
- update fork-history tests and the request snapshot, and add a
`TODO(ccunningham)` for remaining nondiffable initial-context inputs
## Why
Fork startup was appending current-session initial context immediately
after reconstructing the parent rollout, then the first real turn could
emit context updates again. That duplicated model-visible context in the
child rollout.
## Impact
Forked sessions now behave like resume for context seeding: startup
reconstructs history and preserves the prior baseline, and the first
real turn handles any current-session context emission.
---------
Co-authored-by: Codex <noreply@openai.com>
- create `codex-git-utils` and move the shared git helpers into it with
file moves preserved for diff readability
- move the `GitInfo` helpers out of `core` so stacked rollout work can
depend on the shared crate without carrying its own git info module
---------
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
Co-authored-by: Codex <noreply@openai.com>
## Summary
- trim contiguous developer/contextual-user pre-turn updates when
rollback cuts back to a user turn
- add a focused history regression test for the trim behavior
- update the rollback request-boundary snapshots to show the fixed
non-duplicating context shape
---------
Co-authored-by: Codex <noreply@openai.com>
built from #14256. PR description from @etraut-openai:
This PR addresses a hole in [PR
11802](https://github.com/openai/codex/pull/11802). The previous PR
assumed that app server clients would respond to token refresh failures
by presenting the user with an error ("you must log in again") and then
not making further attempts to call network endpoints using the expired
token. While they do present the user with this error, they don't
prevent further attempts to call network endpoints and can repeatedly
call `getAuthStatus(refreshToken=true)` resulting in many failed calls
to the token refresh endpoint.
There are three solutions I considered here:
1. Change the getAuthStatus app server call to return a null auth if the
caller specified "refreshToken" on input and the refresh attempt fails.
This will cause clients to immediately log out the user and return them
to the log in screen. This is a really bad user experience. It's also a
breaking change in the app server contract that could break third-party
clients.
2. Augment the getAuthStatus app server call to return an additional
field that indicates the state of "token could not be refreshed". This
is a non-breaking change to the app server API, but it requires
non-trivial changes for all clients to properly handle this new field
properly.
3. Change the getAuthStatus implementation to handle the case where a
token refresh fails by marking the AuthManager's in-memory access and
refresh tokens as "poisoned" so it they are no longer used. This is the
simplest fix that requires no client changes.
I chose option 3.
Here's Codex's explanation of this change:
When an app-server client asks `getAuthStatus(refreshToken=true)`, we
may try to refresh a stale ChatGPT access token. If that refresh fails
permanently (for example `refresh_token_reused`, expired, or revoked),
the old behavior was bad in two ways:
1. We kept the in-memory auth snapshot alive as if it were still usable.
2. Later auth checks could retry refresh again and again, creating a
storm of doomed `/oauth/token` requests and repeatedly surfacing the
same failure.
This is especially painful for app-server clients because they poll auth
status and can keep driving the refresh path without any real chance of
recovery.
This change makes permanent refresh failures terminal for the current
managed auth snapshot without changing the app-server API contract.
What changed:
- `AuthManager` now poisons the current managed auth snapshot in memory
after a permanent refresh failure, keyed to the unchanged `AuthDotJson`.
- Once poisoned, later refresh attempts for that same snapshot fail fast
locally without calling the auth service again.
- The poison is cleared automatically when auth materially changes, such
as a new login, logout, or reload of different auth state from storage.
- `getAuthStatus(includeToken=true)` now omits `authToken` after a
permanent refresh failure instead of handing out the stale cached bearer
token.
This keeps the current auth method visible to clients, avoids forcing an
immediate logout flow, and stops repeated refresh attempts for
credentials that cannot recover.
---------
Co-authored-by: Eric Traut <etraut@openai.com>
Follow up to #15357 by making proactive ChatGPT auth refresh depend on
the access token's JWT expiration instead of treating `last_refresh` age
as the primary source of truth.
## Summary
- replace the second-compaction test fixtures with a single ordered
`/responses` sequence
- assert against the real recorded request order instead of aggregating
per-mock captures
- realign the second-summary assertion to the first post-compaction user
turn where the summary actually appears
## Root cause
`compact_resume_after_second_compaction_preserves_history` collected
requests from multiple `mount_sse_once_match` recorders. Overlapping
matchers could record the same HTTP request more than once, so the test
indexed into a duplicated synthetic list rather than the true request
stream. That made the summary assertion depend on matcher evaluation
order and platform-specific behavior.
## Impact
- makes the flaky test deterministic by removing duplicate request
capture from the assertion path
- keeps the change scoped to the test only
## Validation
- `just fmt`
- `just argument-comment-lint`
- `env -u CODEX_SANDBOX_NETWORK_DISABLED cargo test -p codex-core
compact_resume_after_second_compaction_preserves_history -- --nocapture`
- repeated the same targeted test 10 times
---------
Co-authored-by: Codex <noreply@openai.com>
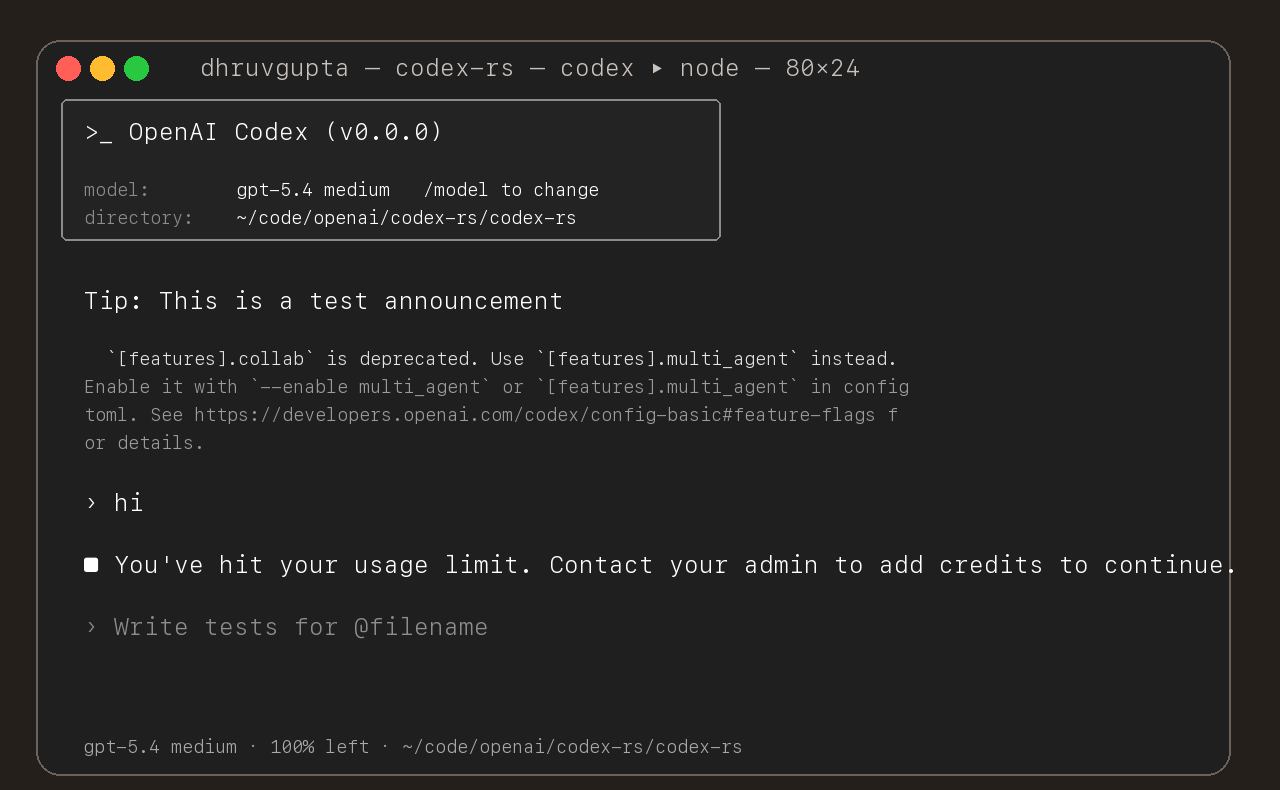
## Summary
- update the self-serve business usage-based limit message to direct
users to their admin for additional credits
- add a focused unit test for the self_serve_business_usage_based plan
branch
Added also:
If you are at a rate limit but you still have credits, codex cli would
tell you to switch the model. We shouldnt do this if you have credits so
fixed this.
## Test
- launched the source-built CLI and verified the updated message is
shown for the self-serve business usage-based plan
## Summary
- add `ForkSnapshotMode` to `ThreadManager::fork_thread` so callers can
request either a committed snapshot or an interrupted snapshot
- share the model-visible `<turn_aborted>` history marker between the
live interrupt path and interrupted forks
- update the small set of direct fork callsites to pass
`ForkSnapshotMode::Committed`
Note: this enables /btw to work similarly as Esc to interrupt (hopefully
somewhat in distribution)
---------
Co-authored-by: Codex <noreply@openai.com>
## What changed
- adds a targeted snapshot test for rollback with contextual diffs in
`codex_tests.rs`
- snapshots the exact model-visible request input before the rolled-back
turn and on the follow-up request after rollback
- shows the duplicate developer and environment context pair appearing
again before the follow-up user message
## Why
Rollback currently rewinds the reference context baseline without
rewinding the live session overrides. On the next turn, the same
contextual diff is emitted again and duplicated in the request sent to
the model.
## Impact
- makes the regression visible in a canonical snapshot test
- keeps the snapshot on the shared `context_snapshot` path without
adding new formatting helpers
- gives a direct repro for future fixes to rollback/context
reconstruction
---------
Co-authored-by: Codex <noreply@openai.com>
## Summary
Adds support for approvals_reviewer to `Op::UserTurn` so we can migrate
`[CodexMessageProcessor::turn_start]` to use Op::UserTurn
## Testing
- [x] Adds quick test for the new field
Co-authored-by: Codex <noreply@openai.com>
- add `PreToolUse` hook for bash-like tool execution only at first
- block shell execution before dispatch with deny-only hook behavior
- introduces common.rs matcher framework for matching when hooks are run
example run:
```
› run three parallel echo commands, and the second one should echo "[block-pre-tool-use]" as a test
• Running the three echo commands in parallel now and I’ll report the output directly.
• Running PreToolUse hook: name for demo pre tool use hook
• Running PreToolUse hook: name for demo pre tool use hook
• Running PreToolUse hook: name for demo pre tool use hook
PreToolUse hook (completed)
warning: wizard-tower PreToolUse demo inspected Bash: echo "first parallel echo"
PreToolUse hook (blocked)
warning: wizard-tower PreToolUse demo blocked a Bash command on purpose.
feedback: PreToolUse demo blocked the command. Remove [block-pre-tool-use] to continue.
PreToolUse hook (completed)
warning: wizard-tower PreToolUse demo inspected Bash: echo "third parallel echo"
• Ran echo "first parallel echo"
└ first parallel echo
• Ran echo "third parallel echo"
└ third parallel echo
• Three little waves went out in parallel.
1. printed first parallel echo
2. was blocked before execution because it contained the exact test string [block-pre-tool-use]
3. printed third parallel echo
There was also an unrelated macOS defaults warning around the successful commands, but the echoes
themselves worked fine. If you want, I can rerun the second one with a slightly modified string so
it passes cleanly.
```
## Summary
Fix a managed ChatGPT auth bug where a stale Codex process could
proactively refresh using an old in-memory refresh token even after
another process had already rotated auth on disk.
This changes the proactive `AuthManager::auth()` path to reuse the
existing guarded `refresh_token()` flow instead of calling the refresh
endpoint directly from cached auth state.
## Original Issue
Users reported repeated `codexd` log lines like:
```text
ERROR codex_core::auth: Failed to refresh token: error sending request for url (https://auth.openai.com/oauth/token)
```
In practice this showed up most often when multiple `codexd` processes
were left running. Killing the extra processes stopped the noise, which
suggested the issue was caused by stale auth state across processes
rather than invalid user credentials.
## Diagnosis
The bug was in the proactive refresh path used by `AuthManager::auth()`:
- Process A could refresh successfully, rotate refresh token `R0` to
`R1`, and persist the updated auth state plus `last_refresh` to disk.
- Process B could keep an older auth snapshot cached in memory, still
holding `R0` and the old `last_refresh`.
- Later, when Process B called `auth()`, it checked staleness from its
cached in-memory auth instead of first reloading from disk.
- Because that cached `last_refresh` was stale, Process B would
proactively call `/oauth/token` with stale refresh token `R0`.
- On failure, `auth()` logged the refresh error but kept returning the
same stale cached auth, so repeated `auth()` calls could keep retrying
with dead state.
This differed from the existing unauthorized-recovery flow, which
already did the safer thing: guarded reload from disk first, then
refresh only if the on-disk auth was unchanged.
## What Changed
- Switched proactive refresh in `AuthManager::auth()` to:
- do a pure staleness check on cached auth
- call `refresh_token()` when stale
- return the original cached auth on genuine refresh failure, preserving
existing outward behavior
- Removed the direct proactive refresh-from-cached-state path
- Added regression tests covering:
- stale cached auth with newer same-account auth already on disk
- the same scenario even when the refresh endpoint would fail if called
## Why This Fix
`refresh_token()` already contains the right cross-process safety
behavior:
- guarded reload from disk
- same-account verification
- skip-refresh when another process already changed auth
Reusing that path makes proactive refresh consistent with unauthorized
recovery and prevents stale processes from trying to refresh
already-rotated tokens.
## Testing
Test shape:
- create a fresh temp `CODEX_HOME` from `~/.codex/auth.json`
- force `last_refresh` to an old timestamp so proactive refresh is
required
- start two long-lived helper processes against the same auth file
- start `B` first so it caches stale auth and sleeps
- start `A` second so it refreshes first
- point both at a local mock `/oauth/token` server
- inspect whether `B` makes a second refresh request with the stale
in-memory token, or reloads the rotated token from disk
### Before the fix
The repro showed the bug clearly: the mock server saw two refreshes with
the same stale token, `A` rotated to a new token, and `B` still returned
the stale token instead of reloading from disk.
```text
POST /oauth/token refresh_token=rt_j6s0...
POST /oauth/token refresh_token=rt_j6s0...
B:cached_before=rt_j6s0...
B:cached_after=rt_j6s0...
B:returned=rt_j6s0...
A:cached_before=rt_j6s0...
A:cached_after=rotated-refresh-token-logged-run-v2
A:returned=rotated-refresh-token-logged-run-v2
```
### After the fix
After the fix, the mock server saw only one refresh request. `A`
refreshed once, and `B` started with the stale token but reloaded and
returned the rotated token.
```text
POST /oauth/token refresh_token=rt_j6s0...
B:cached_before=rt_j6s0...
B:cached_after=rotated-refresh-token-fix-branch
B:returned=rotated-refresh-token-fix-branch
A:cached_before=rt_j6s0...
A:cached_after=rotated-refresh-token-fix-branch
A:returned=rotated-refresh-token-fix-branch
```
This shows the new behavior: `A` refreshes once, then `B` reuses the
updated auth from disk instead of making a second refresh request with
the stale token.
Moves Code Mode to a new crate with no dependencies on codex. This
create encodes the code mode semantics that we want for lifetime,
mounting, tool calling.
The model-facing surface is mostly unchanged. `exec` still runs raw
JavaScript, `wait` still resumes or terminates a `cell_id`, nested tools
are still available through `tools.*`, and helpers like `text`, `image`,
`store`, `load`, `notify`, `yield_control`, and `exit` still exist.
The major change is underneath that surface:
- Old code mode was an external Node runtime.
- New code mode is an in-process V8 runtime embedded directly in Rust.
- Old code mode managed cells inside a long-lived Node runner process.
- New code mode manages cells in Rust, with one V8 runtime thread per
active `exec`.
- Old code mode used JSON protocol messages over child stdin/stdout plus
Node worker-thread messages.
- New code mode uses Rust channels and direct V8 callbacks/events.
This PR also fixes the two migration regressions that fell out of that
substrate change:
- `wait { terminate: true }` now waits for the V8 runtime to actually
stop before reporting termination.
- synchronous top-level `exit()` now succeeds again instead of surfacing
as a script error.
---
- `core/src/tools/code_mode/*` is now mostly an adapter layer for the
public `exec` / `wait` tools.
- `code-mode/src/service.rs` owns cell sessions and async control flow
in Rust.
- `code-mode/src/runtime/*.rs` owns the embedded V8 isolate and
JavaScript execution.
- each `exec` spawns a dedicated runtime thread plus a Rust
session-control task.
- helper globals are installed directly into the V8 context instead of
being injected through a source prelude.
- helper modules like `tools.js` and `@openai/code_mode` are synthesized
through V8 module resolution callbacks in Rust.
---
Also added a benchmark for showing the speed of init and use of a code
mode env:
```
$ cargo bench -p codex-code-mode --bench exec_overhead -- --samples 30 --warm-iterations 25 --tool-counts 0,32,128
Finished [`bench` profile [optimized]](https://doc.rust-lang.org/cargo/reference/profiles.html#default-profiles) target(s) in 0.18s
Running benches/exec_overhead.rs (target/release/deps/exec_overhead-008c440d800545ae)
exec_overhead: samples=30, warm_iterations=25, tool_counts=[0, 32, 128]
scenario tools samples warmups iters mean/exec p95/exec rssΔ p50 rssΔ max
cold_exec 0 30 0 1 1.13ms 1.20ms 8.05MiB 8.06MiB
warm_exec 0 30 1 25 473.43us 512.49us 912.00KiB 1.33MiB
cold_exec 32 30 0 1 1.03ms 1.15ms 8.08MiB 8.11MiB
warm_exec 32 30 1 25 509.73us 545.76us 960.00KiB 1.30MiB
cold_exec 128 30 0 1 1.14ms 1.19ms 8.30MiB 8.34MiB
warm_exec 128 30 1 25 575.08us 591.03us 736.00KiB 864.00KiB
memory uses a fresh-process max RSS delta for each scenario
```
---------
Co-authored-by: Codex <noreply@openai.com>
This PR add an URI-based system to reference agents within a tree. This
comes from a sync between research and engineering.
The main agent (the one manually spawned by a user) is always called
`/root`. Any sub-agent spawned by it will be `/root/agent_1` for example
where `agent_1` is chosen by the model.
Any agent can contact any agents using the path.
Paths can be used either in absolute or relative to the calling agents
Resume is not supported for now on this new path
`CODEX_TEST_REMOTE_ENV` will make `test_codex` start the executor
"remotely" (inside a docker container) turning any integration test into
remote test.
- Split the feature system into a new `codex-features` crate.
- Cut `codex-core` and workspace consumers over to the new config and
warning APIs.
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
Co-authored-by: Codex <noreply@openai.com>
- Move the auth implementation and token data into codex-login.
- Keep codex-core re-exporting that surface from codex-login for
existing callers.
---------
Co-authored-by: Codex <noreply@openai.com>
## Summary
Some background. We're looking to instrument GA turns end to end. Right
now a big gap is grouping mcp tool calls with their codex sessions. We
send session id and turn id headers to the responses call but not the
mcp/wham calls.
Ideally we could pass the args as headers like with responses, but given
the setup of the rmcp client, we can't send as headers without either
changing the rmcp package upstream to allow per request headers or
introducing a mutex which break concurrency. An earlier attempt made the
assumption that we had 1 client per thread, which allowed us to set
headers at the start of a turn. @pakrym mentioned that this assumption
might break in the near future.
So the solution now is to package the turn metadata/session id into the
_meta field in the post body and pull out in codex-backend.
- send turn metadata to MCP servers via `tools/call` `_meta` instead of
assuming per-thread request headers on shared clients
- preserve the existing `_codex_apps` metadata while adding
`x-codex-turn-metadata` for all MCP tool calls
- extend tests to cover both custom MCP servers and the codex apps
search flow
---------
Co-authored-by: Codex <noreply@openai.com>
## Summary
Persist Stop-hook continuation prompts as `user` messages instead of
hidden `developer` messages + some requested integration tests
This is a followup to @pakrym 's comment in
https://github.com/openai/codex/pull/14532 to make sure stop-block
continuation prompts match training for turn loops
- Stop continuation now writes `<hook_prompt hook_run_id="...">stop
hook's user prompt<hook_prompt>`
- Introduces quick-xml dependency, though we already indirectly depended
on it anyway via syntect
- This PR only has about 500 lines of actual logic changes, the rest is
tests/schema
## Testing
Example run (with a sessionstart hook and 3 stop hooks) - this shows
context added by session start, then two stop hooks sending their own
additional prompts in a new turn. The model responds with a single
message addressing both. Then when that turn ends, the hooks detect that
they just ran using `stop_hook_active` and decide not to infinite loop
test files for this (unzip, move codex -> .codex):
[codex.zip](https://github.com/user-attachments/files/26075806/codex.zip)
```
› cats
• Running SessionStart hook: lighting the observatory
SessionStart hook (completed)
warning: Hi, I'm a session start hook for wizard-tower (startup).
hook context: A wimboltine stonpet is an exotic cuisine from hyperspace
• Cats are tiny zen wizards, my friend: equal parts nap, mystery, and chaos. If you want, we can talk
cat facts, cat breeds, cat names, or build something cat-themed in this repo.
• Running Stop hook: checking the tower wards
• Running Stop hook: sacking the guards
• Running Stop hook: hiring the guards
Stop hook (completed)
warning: Wizard Tower Stop hook reviewed the completed reply (177 chars).
Stop hook (blocked)
warning: Wizard Tower Stop hook continuing conversation
feedback: cook the stonpet
Stop hook (blocked)
warning: Wizard Tower Stop hook continuing conversation
feedback: eat the cooked stonpet
• Stonpet’s cooked, aloha style: flash-seared over a blue quasiflame, glazed with nebula salt, and
rested until the hyperspace juices settle.
Now we eat with gratitude, my friend. One mindful bite in, and the flavor is pure cosmic surf:
smoky, bright, and totally out of this dimension.
• Running Stop hook: checking the tower wards
• Running Stop hook: sacking the guards
• Running Stop hook: hiring the guards
Stop hook (completed)
warning: Wizard Tower Stop hook reviewed the completed reply (285 chars).
Stop hook (completed)
warning: Wizard Tower Stop hook saw a second pass and stayed calm to avoid a loop.
Stop hook (completed)
warning: Wizard Tower Stop hook saw a second pass and stayed calm to avoid a loop.
```
## Description
Adding an extension to the spec that exposes the turn_id to hook
scripts. This is a codex-specific mechanic that allows connecting the
hook runs with particular turns
## Testing
hooks config / sample hooks to use. Extract this, rename codex ->
.codex, and place this into a repo or your home folder. It includes:
config.toml that enables hooks, hooks.json, and sample python hooks:
[codex.zip](https://github.com/user-attachments/files/26102671/codex.zip)
example run (note the turn_ids change between turns):
```
› hello
• Running SessionStart hook: lighting the observatory
SessionStart hook (completed)
warning: Hi, I'm a session start hook for wizard-tower (startup).
hook context: Startup context: A wimboltine stonpet is an exotic cuisine from hyperspace
• Running UserPromptSubmit hook: lighting the observatory lanterns
UserPromptSubmit hook (completed)
warning: wizard-tower UserPromptSubmit demo inspected: hello for turn: 019d036d-c7fa-72d2-b6fd-
78878bfe34e4
hook context: Wizard Tower UserPromptSubmit demo fired. For this reply only, include the exact
phrase 'observatory lanterns lit' near the end.
• Aloha! Grateful to be here and ready to build with you. Show me what you want to tackle in wizard-
tower, and we’ll surf the next wave together. observatory lanterns lit
• Running Stop hook: back to shore
Stop hook (completed)
warning: Wizard Tower Stop hook reviewed the completed reply (170 chars) for turn: 019d036d-c7fa-
72d2-b6fd-78878bfe34e4
› what's a stonpet?
• Running UserPromptSubmit hook: lighting the observatory lanterns
UserPromptSubmit hook (completed)
warning: wizard-tower UserPromptSubmit demo inspected: what's a stonpet? for turn: 019d036e-3164-
72c3-a170-98925564c4fc
hook context: Wizard Tower UserPromptSubmit demo fired. For this reply only, include the exact
phrase 'observatory lanterns lit' near the end.
• A stonpet isn’t a standard real-world word, brah. In our shared context here, a wimboltine stonpet
is an exotic cuisine from hyperspace, so “stonpet” sounds like the dish or food itself.
If you want, we can totally invent the lore for it next. observatory lanterns lit
• Running Stop hook: back to shore
Stop hook (completed)
warning: Wizard Tower Stop hook reviewed the completed reply (271 chars) for turn: 019d036e-3164-
72c3-a170-98925564c4fc
```
## Description
Dependent on:
- [responsesapi] https://github.com/openai/openai/pull/760991
- [codex-backend] https://github.com/openai/openai/pull/760985
`codex app-server -> codex-backend -> responsesapi` now reuses a
persistent websocket connection across many turns. This PR updates
tracing when using websockets so that each `response.create` websocket
request propagates the current tracing context, so we can get a holistic
end-to-end trace for each turn.
Tracing is propagated via special keys (`ws_request_header_traceparent`,
`ws_request_header_tracestate`) set in the `client_metadata` param in
Responses API.
Currently tracing on websockets is a bit broken because we only set
tracing context on ws connection time, so it's detached from a
`turn/start` request.
## Summary
- store a pre-rendered `feedback_log_body` in SQLite so `/feedback`
exports keep span prefixes and structured event fields
- render SQLite feedback exports with timestamps and level prefixes to
match the old in-memory feedback formatter, while preserving existing
trailing newlines
- count `feedback_log_body` in the SQLite retention budget so structured
or span-prefixed rows still prune correctly
- bound `/feedback` row loading in SQL with the retention estimate, then
apply exact whole-line truncation in Rust so uploads stay capped without
splitting lines
## Details
- add a `feedback_log_body` column to `logs` and backfill it from
`message` for existing rows
- capture span names plus formatted span and event fields at write time,
since SQLite does not retain enough structure to reconstruct the old
formatter later
- keep SQLite feedback queries scoped to the requested thread plus
same-process threadless rows
- restore a SQL-side cumulative `estimated_bytes` cap for feedback
export queries so over-retained partitions do not load every matching
row before truncation
- add focused formatting coverage for exported feedback lines and parity
coverage against `tracing_subscriber`
## Testing
- cargo test -p codex-state
- just fix -p codex-state
- just fmt
codex author: `codex resume 019ca1b0-0ecc-78b1-85eb-6befdd7e4f1f`
---------
Co-authored-by: Codex <noreply@openai.com>
- prefix realtime handoff output with the agent final message label for
both realtime v1 and v2
- update realtime websocket and core expectations to match
Cleanup image semantics in code mode.
`view_image` now returns `{image_url:string, details?: string}`
`image()` now allows both string parameter and `{image_url:string,
details?: string}`
## Summary
If a subagent requests approval, and the user persists that approval to
the execpolicy, it should (by default) propagate. We'll need to rethink
this a bit in light of coming Permissions changes, though I think this
is closer to the end state that we'd want, which is that execpolicy
changes to one permissions profile should be synced across threads.
## Testing
- [x] Added integration test
---------
Co-authored-by: Codex <noreply@openai.com>
- this allows blocking the user's prompts from executing, and also
prevents them from entering history
- handles the edge case where you can both prevent the user's prompt AND
add n amount of additionalContexts
- refactors some old code into common.rs where hooks overlap
functionality
- refactors additionalContext being previously added to user messages,
instead we use developer messages for them
- handles queued messages correctly
Sample hook for testing - if you write "[block-user-submit]" this hook
will stop the thread:
example run
```
› sup
• Running UserPromptSubmit hook: reading the observatory notes
UserPromptSubmit hook (completed)
warning: wizard-tower UserPromptSubmit demo inspected: sup
hook context: Wizard Tower UserPromptSubmit demo fired. For this reply only, include the exact
phrase 'observatory lanterns lit' exactly once near the end.
• Just riding the cosmic wave and ready to help, my friend. What are we building today? observatory
lanterns lit
› and [block-user-submit]
• Running UserPromptSubmit hook: reading the observatory notes
UserPromptSubmit hook (stopped)
warning: wizard-tower UserPromptSubmit demo blocked the prompt on purpose.
stop: Wizard Tower demo block: remove [block-user-submit] to continue.
```
.codex/config.toml
```
[features]
codex_hooks = true
```
.codex/hooks.json
```
{
"hooks": {
"UserPromptSubmit": [
{
"hooks": [
{
"type": "command",
"command": "/usr/bin/python3 .codex/hooks/user_prompt_submit_demo.py",
"timeoutSec": 10,
"statusMessage": "reading the observatory notes"
}
]
}
]
}
}
```
.codex/hooks/user_prompt_submit_demo.py
```
#!/usr/bin/env python3
import json
import sys
from pathlib import Path
def prompt_from_payload(payload: dict) -> str:
prompt = payload.get("prompt")
if isinstance(prompt, str) and prompt.strip():
return prompt.strip()
event = payload.get("event")
if isinstance(event, dict):
user_prompt = event.get("user_prompt")
if isinstance(user_prompt, str):
return user_prompt.strip()
return ""
def main() -> int:
payload = json.load(sys.stdin)
prompt = prompt_from_payload(payload)
cwd = Path(payload.get("cwd", ".")).name or "wizard-tower"
if "[block-user-submit]" in prompt:
print(
json.dumps(
{
"systemMessage": (
f"{cwd} UserPromptSubmit demo blocked the prompt on purpose."
),
"decision": "block",
"reason": (
"Wizard Tower demo block: remove [block-user-submit] to continue."
),
}
)
)
return 0
prompt_preview = prompt or "(empty prompt)"
if len(prompt_preview) > 80:
prompt_preview = f"{prompt_preview[:77]}..."
print(
json.dumps(
{
"systemMessage": (
f"{cwd} UserPromptSubmit demo inspected: {prompt_preview}"
),
"hookSpecificOutput": {
"hookEventName": "UserPromptSubmit",
"additionalContext": (
"Wizard Tower UserPromptSubmit demo fired. "
"For this reply only, include the exact phrase "
"'observatory lanterns lit' exactly once near the end."
),
},
}
)
)
return 0
if __name__ == "__main__":
raise SystemExit(main())
```
- close live realtime sessions on errors, ctrl-c, and active meter
removal
- centralize TUI realtime cleanup and avoid duplicate follow-up close
info
---------
Co-authored-by: Codex <noreply@openai.com>
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
- route realtime startup, input, and transport failures through a single
shutdown path
- emit one realtime error/closed lifecycle while clearing session state
once
---------
Co-authored-by: Codex <noreply@openai.com>
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
- thread the realtime version into conversation start and app-server
notifications
- keep playback-aware mic gating and playback interruption behavior on
v2 only, leaving v1 on the legacy path
Summary
- document that code mode only exposes `exec` and the renamed `wait`
tool
- update code mode tool spec and descriptions to match the new tool name
- rename tests and helper references from `exec_wait` to `wait`
Testing
- Not run (not requested)
## What is flaky
The approval-matrix `WriteFile` scenario is flaky. It sometimes fails in
CI even though the approval logic is unchanged, because the test
delegates the file write and readback to shell parsing instead of
deterministic file I/O.
## Why it was flaky
The test generated a command shaped like `printf ... > file && cat
file`. That means the scenario depended on shell quoting, redirection,
newline handling, and encoding behavior in addition to the approval
system it was actually trying to validate. If the shell interpreted the
payload differently, the test would report an approval failure even
though the product logic was fine.
That also made failures hard to diagnose, because the test did not log
the exact generated command or the parsed result payload.
## How this PR fixes it
This PR replaces the shell-redirection path with a deterministic
`python3 -c` script that writes the file with `Path.write_text(...,
encoding='utf-8')` and then reads it back with the same UTF-8 path. It
also logs the generated command and the resulting exit code/stdout for
the approval scenario so any future failure is directly attributable.
## Why this fix fixes the flakiness
The scenario no longer depends on shell parsing and redirection
semantics. The file contents are produced and read through explicit
UTF-8 file I/O, so the approval test is measuring approval behavior
instead of shell behavior. The added diagnostics mean a future failure
will show the exact command/result pair instead of looking like a
generic intermittent mismatch.
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
Co-authored-by: Codex <noreply@openai.com>
## What is flaky
The Windows shell-driven integration tests in `codex-rs/core` were
intermittently unstable, especially:
- `apply_patch_cli_can_use_shell_command_output_as_patch_input`
- `websocket_test_codex_shell_chain`
- `websocket_v2_test_codex_shell_chain`
## Why it was flaky
These tests were exercising real shell-tool flows through whichever
shell Codex selected on Windows, and the `apply_patch` test also nested
a PowerShell read inside `cmd /c`.
There were multiple independent sources of nondeterminism in that setup:
- The test harness depended on the model-selected Windows shell instead
of pinning the shell it actually meant to exercise.
- `cmd.exe /c powershell.exe -Command "..."` is quoting-sensitive; on CI
that could leave the read command wrapped as a literal string instead of
executing it.
- Even after getting the quoting right, PowerShell could emit CLIXML
progress records like module-initialization output onto stdout.
- The `apply_patch` test was building a patch directly from shell
stdout, so any quoting artifact or progress noise corrupted the patch
input.
So the failures were driven by shell startup and output-shape variance,
not by the `apply_patch` or websocket logic themselves.
## How this PR fixes it
- Add a test-only `user_shell_override` path so Windows integration
tests can pin `cmd.exe` explicitly.
- Use that override in the websocket shell-chain tests and in the
`apply_patch` harness.
- Change the nested Windows file read in
`apply_patch_cli_can_use_shell_command_output_as_patch_input` to a UTF-8
PowerShell `-EncodedCommand` script.
- Run that nested PowerShell process with `-NonInteractive`, set
`$ProgressPreference = 'SilentlyContinue'`, and read the file with
`[System.IO.File]::ReadAllText(...)`.
## Why this fix fixes the flakiness
The outer harness now runs under a deterministic shell, and the inner
PowerShell read no longer depends on fragile `cmd` quoting or on
progress output staying quiet by accident. The shell tool returns only
the file contents, so patch construction and websocket assertions depend
on stable test inputs instead of on runner-specific shell behavior.
---------
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
Co-authored-by: Codex <noreply@openai.com>
## Description
This PR fixes a bad first-turn failure mode in app-server when the
startup websocket prewarm hangs. Before this change, `initialize ->
thread/start -> turn/start` could sit behind the prewarm for up to five
minutes, so the client would not see `turn/started`, and even
`turn/interrupt` would block because the turn had not actually started
yet.
Now, we:
- set a (configurable) timeout of 15s for websocket startup time,
exposed as `websocket_startup_timeout_ms` in config.toml
- `turn/started` is sent immediately on `turn/start` even if the
websocket is still connecting
- `turn/interrupt` can be used to cancel a turn that is still waiting on
the websocket warmup
- the turn task will wait for the full 15s websocket warming timeout
before falling back
## Why
The old behavior made app-server feel stuck at exactly the moment the
client expects turn lifecycle events to start flowing. That was
especially painful for external clients, because from their point of
view the server had accepted the request but then went silent for
minutes.
## Configuring the websocket startup timeout
Can set it in config.toml like this:
```
[model_providers.openai]
supports_websockets = true
websocket_connect_timeout_ms = 15000
```
## Stack Position
2/4. Built on top of #14828.
## Base
- #14828
## Unblocks
- #14829
- #14827
## Scope
- Port the realtime v2 wire parsing, session, app-server, and
conversation runtime behavior onto the split websocket-method base.
- Branch runtime behavior directly on the current realtime session kind
instead of parser-derived flow flags.
- Keep regression coverage in the existing e2e suites.
---------
Co-authored-by: Codex <noreply@openai.com>
## Why
Once the repo-local lint exists, `codex-rs` needs to follow the
checked-in convention and CI needs to keep it from drifting. This commit
applies the fallback `/*param*/` style consistently across existing
positional literal call sites without changing those APIs.
The longer-term preference is still to avoid APIs that require comments
by choosing clearer parameter types and call shapes. This PR is
intentionally the mechanical follow-through for the places where the
existing signatures stay in place.
After rebasing onto newer `main`, the rollout also had to cover newly
introduced `tui_app_server` call sites. That made it clear the first cut
of the CI job was too expensive for the common path: it was spending
almost as much time installing `cargo-dylint` and re-testing the lint
crate as a representative test job spends running product tests. The CI
update keeps the full workspace enforcement but trims that extra
overhead from ordinary `codex-rs` PRs.
## What changed
- keep a dedicated `argument_comment_lint` job in `rust-ci`
- mechanically annotate remaining opaque positional literals across
`codex-rs` with exact `/*param*/` comments, including the rebased
`tui_app_server` call sites that now fall under the lint
- keep the checked-in style aligned with the lint policy by using
`/*param*/` and leaving string and char literals uncommented
- cache `cargo-dylint`, `dylint-link`, and the relevant Cargo
registry/git metadata in the lint job
- split changed-path detection so the lint crate's own `cargo test` step
runs only when `tools/argument-comment-lint/*` or `rust-ci.yml` changes
- continue to run the repo wrapper over the `codex-rs` workspace, so
product-code enforcement is unchanged
Most of the code changes in this commit are intentionally mechanical
comment rewrites or insertions driven by the lint itself.
## Verification
- `./tools/argument-comment-lint/run.sh --workspace`
- `cargo test -p codex-tui-app-server -p codex-tui`
- parsed `.github/workflows/rust-ci.yml` locally with PyYAML
---
* -> #14652
* #14651
- **Summary**
- expose `exit` through the code mode bridge and module so scripts can
stop mid-flight
- surface the helper in the description documentation
- add a regression test ensuring `exit()` terminates execution cleanly
- **Testing**
- Not run (not requested)
## Summary
- reuse a guardian subagent session across approvals so reviews keep a
stable prompt cache key and avoid one-shot startup overhead
- clear the guardian child history before each review so prior guardian
decisions do not leak into later approvals
- include the `smart_approvals` -> `guardian_approval` feature flag
rename in the same PR to minimize release latency on a very tight
timeline
- add regression coverage for prompt-cache-key reuse without
prior-review prompt bleed
## Request
- Bug/enhancement request: internal guardian prompt-cache and latency
improvement request
---------
Co-authored-by: Codex <noreply@openai.com>
{kind=link}