Migrate `cwd` and related session/config state to `AbsolutePathBuf` so
downstream consumers consistently see absolute working directories.
Add test-only `.abs()` helpers for `Path`, `PathBuf`, and `TempDir`, and
update branch-local tests to use them instead of
`AbsolutePathBuf::try_from(...)`.
For the remaining TUI/app-server snapshot coverage that renders absolute
cwd values, keep the snapshots unchanged and skip the Windows-only cases
where the platform-specific absolute path layout differs.
# External (non-OpenAI) Pull Request Requirements
Before opening this Pull Request, please read the dedicated
"Contributing" markdown file or your PR may be closed:
https://github.com/openai/codex/blob/main/docs/contributing.md
If your PR conforms to our contribution guidelines, replace this text
with a detailed and high quality description of your changes.
Include a link to a bug report or enhancement request.
---------
Co-authored-by: Codex <noreply@openai.com>
- Changed `requires_mcp_tool_approval` to apply MCP spec defaults when
annotations are missing.
- Unannotated tools now default to:
- `readOnlyHint = false`
- `destructiveHint = true`
- `openWorldHint = true`
- This means unannotated MCP tools now go through approval/ARC
monitoring instead of silently bypassing it.
- Explicitly read-only tools still skip approval unless they are also
explicitly marked destructive.
**Previous behavior**
Failed open for missing annotations, which was unsafe for custom MCP
tools that omitted or forgot annotations.
---------
Co-authored-by: colby-oai <228809017+colby-oai@users.noreply.github.com>
## Summary
- remove the fork-startup `build_initial_context` injection
- keep the reconstructed `reference_context_item` as the fork baseline
until the first real turn
- update fork-history tests and the request snapshot, and add a
`TODO(ccunningham)` for remaining nondiffable initial-context inputs
## Why
Fork startup was appending current-session initial context immediately
after reconstructing the parent rollout, then the first real turn could
emit context updates again. That duplicated model-visible context in the
child rollout.
## Impact
Forked sessions now behave like resume for context seeding: startup
reconstructs history and preserves the prior baseline, and the first
real turn handles any current-session context emission.
---------
Co-authored-by: Codex <noreply@openai.com>
- create `codex-git-utils` and move the shared git helpers into it with
file moves preserved for diff readability
- move the `GitInfo` helpers out of `core` so stacked rollout work can
depend on the shared crate without carrying its own git info module
---------
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
Co-authored-by: Codex <noreply@openai.com>
## Summary
- trim contiguous developer/contextual-user pre-turn updates when
rollback cuts back to a user turn
- add a focused history regression test for the trim behavior
- update the rollback request-boundary snapshots to show the fixed
non-duplicating context shape
---------
Co-authored-by: Codex <noreply@openai.com>
built from #14256. PR description from @etraut-openai:
This PR addresses a hole in [PR
11802](https://github.com/openai/codex/pull/11802). The previous PR
assumed that app server clients would respond to token refresh failures
by presenting the user with an error ("you must log in again") and then
not making further attempts to call network endpoints using the expired
token. While they do present the user with this error, they don't
prevent further attempts to call network endpoints and can repeatedly
call `getAuthStatus(refreshToken=true)` resulting in many failed calls
to the token refresh endpoint.
There are three solutions I considered here:
1. Change the getAuthStatus app server call to return a null auth if the
caller specified "refreshToken" on input and the refresh attempt fails.
This will cause clients to immediately log out the user and return them
to the log in screen. This is a really bad user experience. It's also a
breaking change in the app server contract that could break third-party
clients.
2. Augment the getAuthStatus app server call to return an additional
field that indicates the state of "token could not be refreshed". This
is a non-breaking change to the app server API, but it requires
non-trivial changes for all clients to properly handle this new field
properly.
3. Change the getAuthStatus implementation to handle the case where a
token refresh fails by marking the AuthManager's in-memory access and
refresh tokens as "poisoned" so it they are no longer used. This is the
simplest fix that requires no client changes.
I chose option 3.
Here's Codex's explanation of this change:
When an app-server client asks `getAuthStatus(refreshToken=true)`, we
may try to refresh a stale ChatGPT access token. If that refresh fails
permanently (for example `refresh_token_reused`, expired, or revoked),
the old behavior was bad in two ways:
1. We kept the in-memory auth snapshot alive as if it were still usable.
2. Later auth checks could retry refresh again and again, creating a
storm of doomed `/oauth/token` requests and repeatedly surfacing the
same failure.
This is especially painful for app-server clients because they poll auth
status and can keep driving the refresh path without any real chance of
recovery.
This change makes permanent refresh failures terminal for the current
managed auth snapshot without changing the app-server API contract.
What changed:
- `AuthManager` now poisons the current managed auth snapshot in memory
after a permanent refresh failure, keyed to the unchanged `AuthDotJson`.
- Once poisoned, later refresh attempts for that same snapshot fail fast
locally without calling the auth service again.
- The poison is cleared automatically when auth materially changes, such
as a new login, logout, or reload of different auth state from storage.
- `getAuthStatus(includeToken=true)` now omits `authToken` after a
permanent refresh failure instead of handing out the stale cached bearer
token.
This keeps the current auth method visible to clients, avoids forcing an
immediate logout flow, and stops repeated refresh attempts for
credentials that cannot recover.
---------
Co-authored-by: Eric Traut <etraut@openai.com>
Follow up to #15357 by making proactive ChatGPT auth refresh depend on
the access token's JWT expiration instead of treating `last_refresh` age
as the primary source of truth.
## Summary
- replace the second-compaction test fixtures with a single ordered
`/responses` sequence
- assert against the real recorded request order instead of aggregating
per-mock captures
- realign the second-summary assertion to the first post-compaction user
turn where the summary actually appears
## Root cause
`compact_resume_after_second_compaction_preserves_history` collected
requests from multiple `mount_sse_once_match` recorders. Overlapping
matchers could record the same HTTP request more than once, so the test
indexed into a duplicated synthetic list rather than the true request
stream. That made the summary assertion depend on matcher evaluation
order and platform-specific behavior.
## Impact
- makes the flaky test deterministic by removing duplicate request
capture from the assertion path
- keeps the change scoped to the test only
## Validation
- `just fmt`
- `just argument-comment-lint`
- `env -u CODEX_SANDBOX_NETWORK_DISABLED cargo test -p codex-core
compact_resume_after_second_compaction_preserves_history -- --nocapture`
- repeated the same targeted test 10 times
---------
Co-authored-by: Codex <noreply@openai.com>
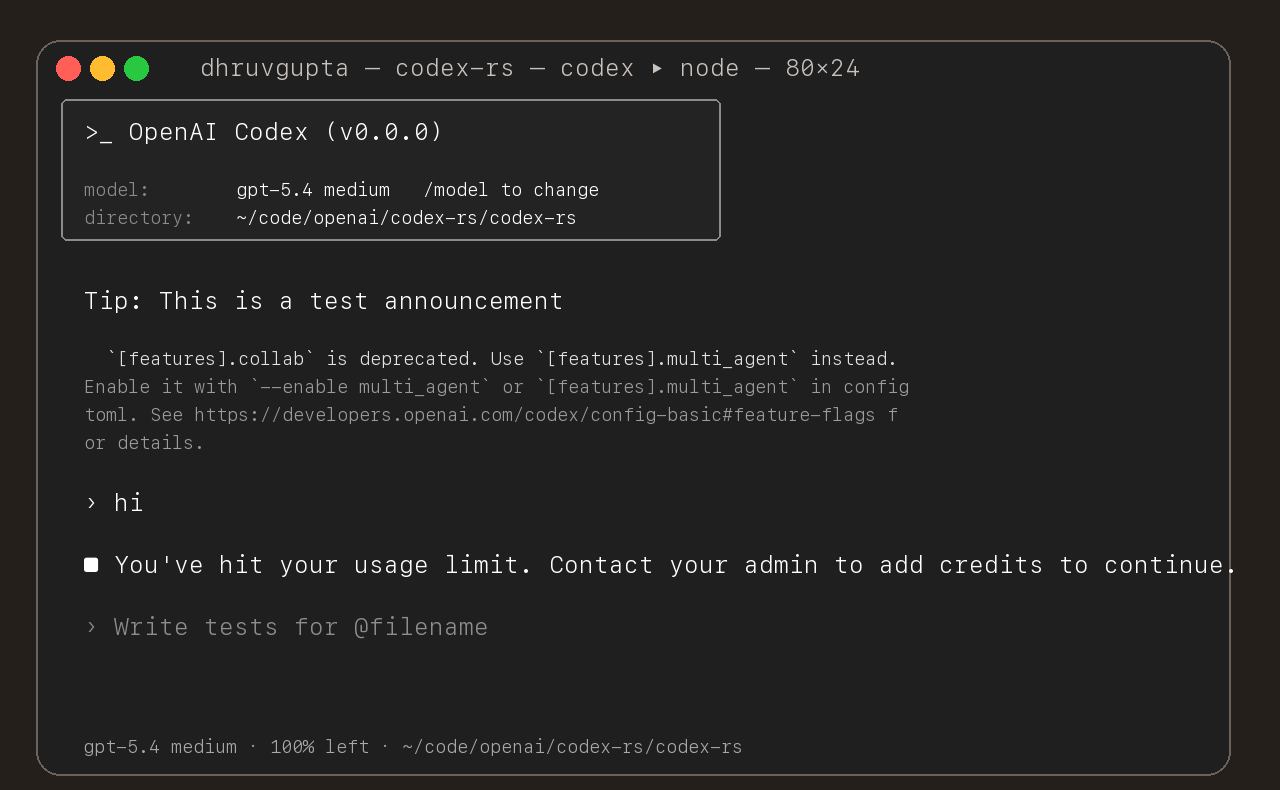
## Summary
- update the self-serve business usage-based limit message to direct
users to their admin for additional credits
- add a focused unit test for the self_serve_business_usage_based plan
branch
Added also:
If you are at a rate limit but you still have credits, codex cli would
tell you to switch the model. We shouldnt do this if you have credits so
fixed this.
## Test
- launched the source-built CLI and verified the updated message is
shown for the self-serve business usage-based plan
## Summary
- add `ForkSnapshotMode` to `ThreadManager::fork_thread` so callers can
request either a committed snapshot or an interrupted snapshot
- share the model-visible `<turn_aborted>` history marker between the
live interrupt path and interrupted forks
- update the small set of direct fork callsites to pass
`ForkSnapshotMode::Committed`
Note: this enables /btw to work similarly as Esc to interrupt (hopefully
somewhat in distribution)
---------
Co-authored-by: Codex <noreply@openai.com>
{kind=link}